




























kafkaintherun
who tells the birds where to fly?
Lens at Work:
A Day in Chinatown, Manhattan New York.








Recent Posts
-
The Long Way Back

I do not buy the ticket. I keep the boy a boy, I keep the tree, and the light switch exactly where my hand remembers. I keep a house where the hinge still complains. I keep a lane the rain has not yet hardened. I keep my mother’s voice in the next room, counting something,…
-
शीर्षकविहीन

तर म जान्दछु, म पुग्दा मेरो घरले मलाई चिन्ने छैन। भित्ता पोतिएको हुनेछ। चौखटले मलाई नचिनी बस्नेछ। चुकुल अहिले कसैले तेल हालिसक्यो होला। बत्तीको स्विच अर्कैको हातले भेट्टाउने छ। र म उभिनेछु, पाहुना भएर, आफ्नै आँगनमा।
-
marginalia

A poem about loving the letter more than the sending – and the letter that goes out everywhere but to you.
-
The Story of Roman Britain Part I: The Work of Giants

The Saxons had a phrase for the ruins the Romans left behind: enta geweorc — the work of giants. Standing before stone arches no living craftsman could replicate, they could not bring themselves to believe a human hand had laid them. They were right to be humbled. Rome ruled Britain for nearly four hundred years,…
-
The Name I once wore

Oh, the wind is a thief and the mountains are tall, And I’m just a witness to the rise and the fall. I’m tracing the shadows where the memory stays, Trading my tomorrows for my yesterdays.
-
मिनपचासको जाडोमा कठ्यांग्रिएको देश

मिनपचासको जाडोमा कठ्याङ्ग्रिएको देश- यहाँ मौसम होइन, विवेक चिसिएको छ। अफसोस, हामीलाई त कठ्यांग्रिनुमै ‘निशाचर’ आनन्द छ।
-
Happy Birthday

I found you a year ago on this day, and I promised to wish you not virtually the next time around. I failed the geography of that promise, but not the truth of it. This is not just pixels on a screen. It is a heartbeat sent across the wire.
-
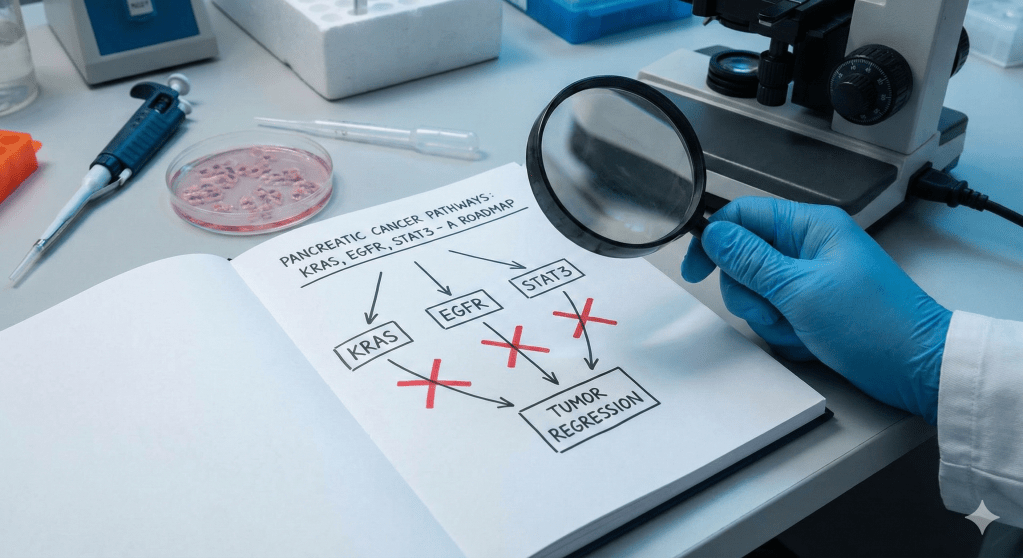
The Architecture of a Cure: Why Spain’s Pancreatic Cancer Breakthrough Is Both a Triumph and a Cautionary Tale
A major breakthrough from Spain’s CNIO claims to cure pancreatic cancer in mice. This analysis explains the ‘triple blockade’ science and why the road to human trials is still long and risky. Read the full reality check.
-
अब रमिता छ

इतिहासले सोध्नेछ, त्यो कालो सेप्टेम्बरपछि देशमा के फेरियो? थाहा छैन हामी के भन्नेछौँ, यहाँ जब सुसासन खोज्दै बितेका सपनाहरू निर्वाचनको कच्चा पदार्थ बनाएर नयाँ मसिहाहरूले बोक्न थालेका छन्। म आक्रोशित छैन, आक्रोश त ऊर्जा हो। म थाकेको छु, रियालिटी सो बनेको देशमा नयाँ भविष्यको विपनाले, अब रमिता छ।
-
Faith Before Hunger: When the Temple Birthed the Village and the Farm

Did faith hatch before the farm? Discover how 13,000-year-old ruins at Göbekli Tepe and Boncuklu Tarla are rewriting human history?
- Articles (26)
- English (29)
- English Poetry (9)
- History (14)
- Letters (6)
- Monologues (8)
- Musings (31)
- Nepali (53)
- Nepali literature (46)
- Nepali Poetry (48)
- Poetry (52)
- Ramblings (47)
- Science (8)
- Stories (2)
- June 2026 (3)
- May 2026 (1)
- April 2026 (1)
- February 2026 (2)
- January 2026 (8)
- December 2025 (6)
- November 2025 (6)
- October 2025 (6)
- September 2025 (2)
- August 2025 (7)
- July 2025 (3)
- June 2025 (4)
- May 2025 (4)
- April 2025 (27)
- March 2025 (6)
- December 2024 (1)
- October 2024 (1)
- September 2024 (1)
- March 2023 (1)
- February 2023 (1)
Akkad (5) Biology (5) hinduism (6) History (10) literature (61) love (8) love poems (7) Mesopotamia (6) muse (25) Musing (24) Nepal (34) Nepali (5) Nepali Poetry (6) nepali politics (19) Nepali Society (4) New York (12) nostalgia (6) Poetry (58) politics (4) random musing (31) romance (10) romantic (5) Science (5) Sumer (7) Writing (44) कविता (6) नेपाल (41) नेपाली कविता (21) नेपाली राजनीति (4) नेपाली साहित्य (5)
who tells the birds where to fly?
© 2025 all rights reserved. Designed with WordPress.
